Speech Processing System (SPSTM)
We developed several independent modules in this system. Here we will briefly describe each one of them, followed by demos for each module. Finally, we include two complete demos by combining all the components together.
VSepTM
A blind source separation module has been implemented. The module does not require signal location and direction information.
Two microphones are needed. The inputs to this module are two wav files from two microphones and the outputs are separated signals in wav format. The algorithm was implemented in the frequency domain so that convolutive mixtures can be separated. The module is not depending on any commercial package and the algorithm was implemented in C. The upper left shows the input signals from the two microphones. A pop-up window can allow user to listen to the signals before and after separation. It can be seen that the separated signals have much better quality than the mixed counterparts.
Demo video file can be found in the Download section.
Adaptive-VSepTM
Compared to VSepTM, this adaptive tool has on-line learning capability to improve the separation of signals. It is also applicable to environments with moderate reverberations. The C-executable files were embedded in modules.
Similar to VSepTM, this module takes two wav files as inputs and outputs the separated wav files.
Demo video file can be found in the Download section.
Spatial-SepTM
Here a spatial signal separation approach was implemented. An array of microphones is used to create beampatten that spatially filters unwanted signals and retains the desired signals from certain directions.
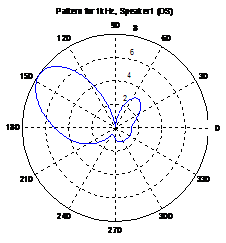
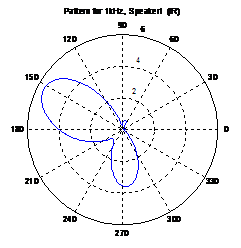
The beamformer has interference rejection capability. That is, a null is created in the interferer’s direction. The beampatterns of two beamformers are shown here. In the demo, the beamformer with interference rejection (IR) was adopted. Upper left sub-window in the demo shows the microphone signals. There are 8 microphones. After spatial filtering, a pop-up window shows up to allow users to listen to the signals before and after spatial filtering. It can be seen that the rejection performance is excellent. In addition, the processing speed is about 1.5 seconds.
Beampatterns of two beamformers: Left (DS); Right (IR). DS still has residual gain in the speaker 2 direction whereas IR has close to zero gain in that direction.
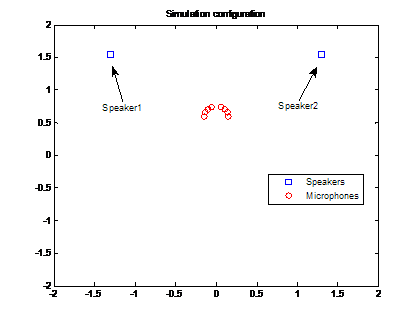
Locations of mics and speakers
Demo video file can be found in the Download section.
Speaker-IDTM
A Gaussian Mixture Model (GMM) based speaker identification module was implemented in C. The input to the module is a wav file and the output of the module is the speaker id number. See figure below. A 4-speaker model is adopted in this demo. The scores are computed and highest one is selected as the id number of the speaker.
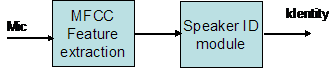
Demo video file can be found in the Download section.
SpeechRegTM
A Hidden Markov Model (HMM) based speech recognizer was implemented in C. The input to the module is a wav file and the recognized outputs are displayed on a GUI.
Demo video file can be found in the Download section.
Integrated system demos
In multiple speakers environment, the mixed voices will seriously affect the speaker identification and speech recognition performance. Here we include a demo where the mixed signals from 8 mics are separated first, then the speech features are extracted, and finally the speaker id and speech content are extracted.

Demo video file can be found in the Download section.